from sktime import *
from sktime.datasets import load_airline
from sktime.utils.plotting import plot_series
y = load_airline()
plot_series(y)(<Figure size 1536x384 with 1 Axes>,
<AxesSubplot: ylabel='Number of airline passengers'>)
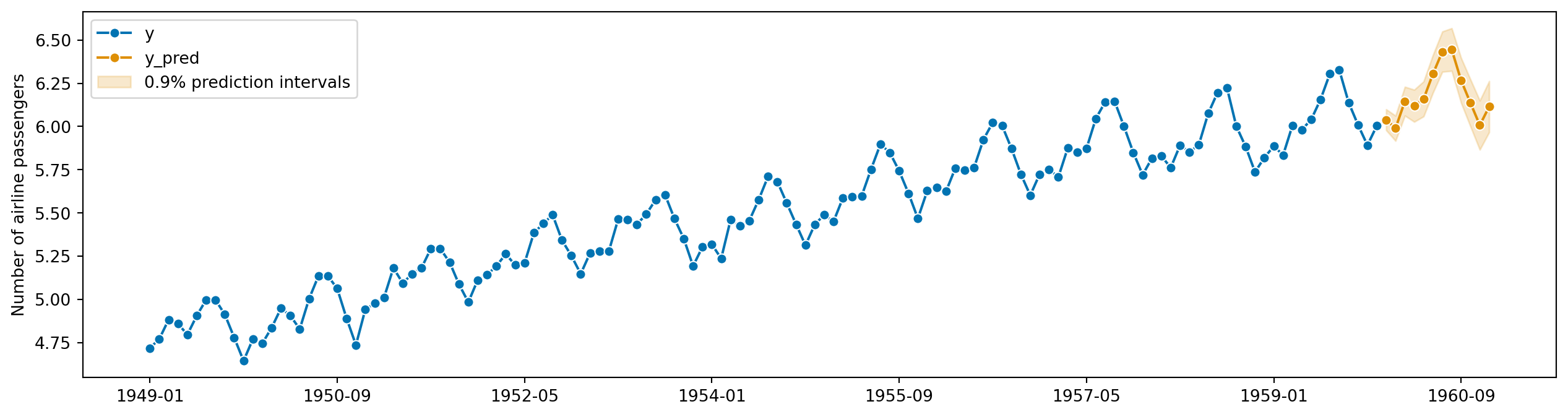
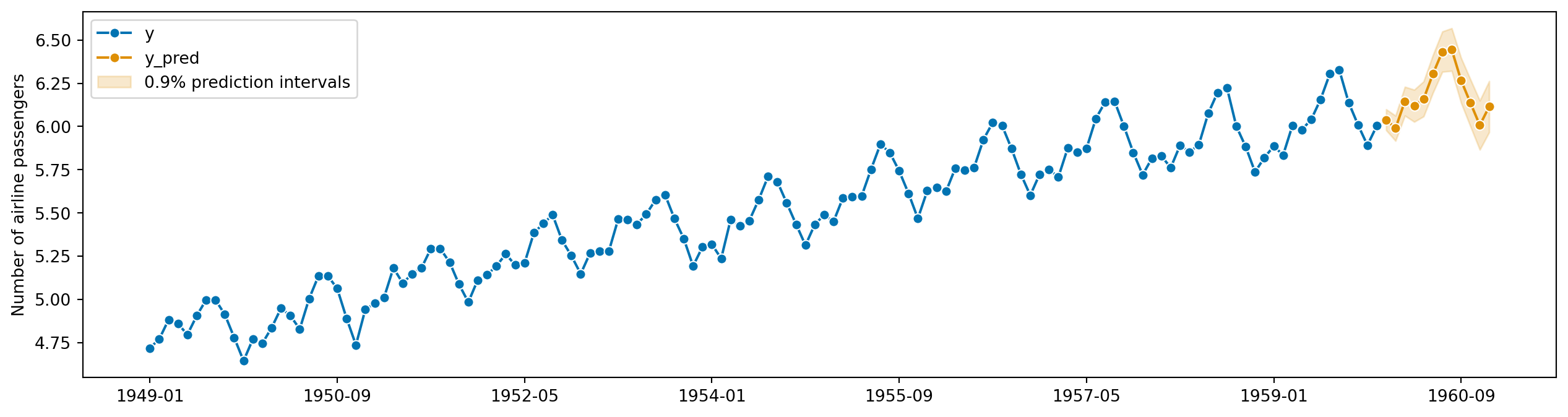
y_test.naturallog = np.log(y_test)
from sktime.utils import plotting
# also requires predictions
y_pred = forecaster.predict()
fig, ax = plotting.plot_series(y_train.naturallog, y_pred, labels=["y", "y_pred"])
ax.fill_between(
ax.get_lines()[-1].get_xdata(),
y_pred_ints["Coverage"][coverage]["lower"],
y_pred_ints["Coverage"][coverage]["upper"],
alpha=0.2,
color=ax.get_lines()[-1].get_c(),
label=f"{coverage}% prediction intervals",
)
ax.legend();